
AI video products rarely fail because of model quality. In practice, they fail because the surrounding system is not designed to handle the operational realities of video: large file ingestion, long-running asynchronous workloads, partial failures, pricing enforcement, and user interfaces that must communicate progress clearly without exposing unnecessary complexity.
LuminaCore AI was designed with these constraints as first-class architectural inputs. Rather than treating AI processing as a single pipeline, LuminaCore AI is built as a platform that supports multiple AI video engines with different user expectations, economic models, and backend workflows, while still sharing a common operational foundation.
This post explains the platform architecture at the system and interface levels. It intentionally avoids proprietary AI internals and instead focuses on the architectural decisions that allow the product to operate reliably in production.
What LuminaCore AI is, architecturally
At a high level, LuminaCore AI consists of a Next.js web application that fronts a Spring Boot backend API, together serving as the system's control plane. This control plane coordinates authentication, video ingestion, job orchestration, pricing enforcement, status tracking, and result delivery.
Critically, the backend is not responsible for moving large video payloads. Video data flows directly from the browser to object storage, while the backend remains focused on metadata, validation, and orchestration. This separation is fundamental to scalability and reliability.
The platform currently supports two AI video engines, each built on the same shared foundation but diverging intentionally where business logic and system guarantees differ.
Two engines built on a shared platform
Campaign engine
The Campaign Engine generates short-form, platform-specific outputs such as social media clips, marketing copy, and subtitles or translations. It operates on a credit-based economic model, where users consume credits under a subscription or a pre-purchased balance.
Credits are checked and deducted before processing begins, ensuring the system provides predictable usage behaviour and avoids ambiguous billing outcomes during long-running jobs.
Summarization engine
The Summarisation Engine produces video summaries, key points, and highlights with timestamps. It operates on a pay-per-use model, priced per minute of video, and is billed via Stripe Payment Intents.
In this engine, payment confirmation is a strict prerequisite for job execution. No compute is scheduled until payment has been successfully authorised, ensuring clear cost attribution and strong guarantees on compute spend.
Shared foundation with intentional divergence
Although the two engines differ in behaviour and economics, they are not separate systems. They are extensions of a shared platform layer that provides common services, including authentication, uploads, job tracking, status reporting, results storage, and observability.
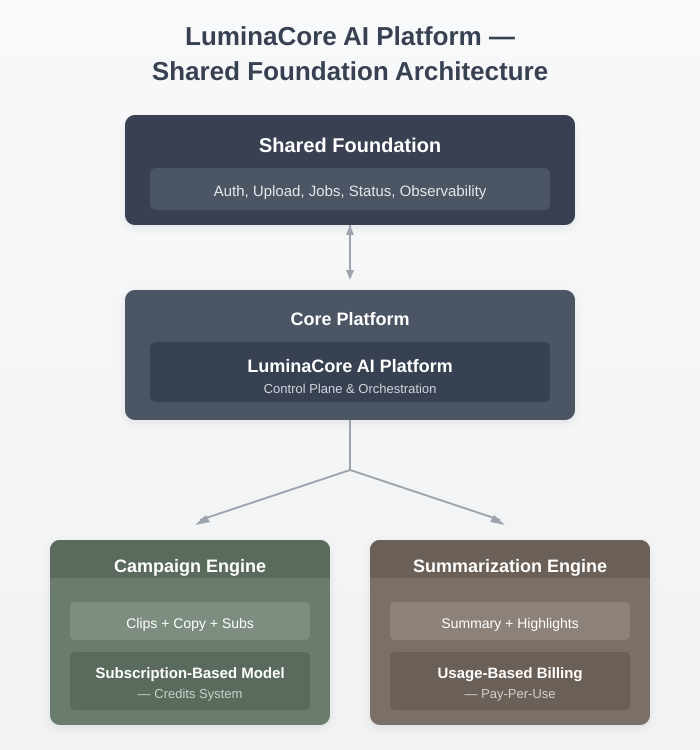
This diagram illustrates the shared platform foundation that underpins all LuminaCore AI engines. Common services are implemented once and reused consistently, while each engine extends the platform only where business logic and economic contracts require it.
This structure allows LuminaCore AI to support multiple engines without duplicating infrastructure or introducing accidental complexity.
Logical system architecture: end-to-end view
From an execution standpoint, LuminaCore AI follows a clear separation of responsibilities. The browser uploads video assets directly to cloud storage using presigned URLs. The backend API serves as the control plane, validating requests, creating jobs, enforcing pricing rules, and exposing job status and results. AI processing runs asynchronously and reports progress to the system via well-defined job states.
This design avoids backend bottlenecks, simplifies failure handling, and allows long-running workflows to progress independently of user sessions.
Why this architectural split works
This separation of responsibilities is intentional.
Large video assets are streamed directly from the browser to object storage, avoiding backend payload bottlenecks and enabling uploads to scale independently of API throughput. The backend remains focused on control-plane responsibilities, such as metadata validation, job creation, accounting, and orchestration triggers, rather than serving as a data transport layer.
The frontend remains reliable and maintainable because it interacts with the backend through a typed, layered API surface. This structure allows long-running workflows, retries, and partial failures to be handled predictably as the system evolves.
Pricing as an architectural concern
Pricing in LuminaCore AI is not a billing detail layered on top of processing logic. It directly shapes how jobs are created, validated, and executed.
In the Campaign Engine, the system verifies and deducts credits before job execution, ensuring that compute usage always aligns with a user's available balance. In the Summarisation Engine, job creation is gated on successful payment confirmation, preventing ambiguity around cost responsibility.
These differences result in distinct job state machines, UX flows, and operational guarantees. Encoding them directly into the architecture avoids downstream complexity and makes system behavior predictable under failure or retry conditions.
The frontend as a control-plane participant
In LuminaCore AI, the frontend is not treated as a passive rendering layer. It actively participates in distributed workflows that include large-file uploads, payment orchestration, and long-running asynchronous jobs.
To support this, the frontend is intentionally layered. UI components interact with domain-specific hooks, which delegate to service layers and a typed HTTP client responsible for authentication, retries, and error normalisation. This structure allows the frontend to evolve alongside the backend without becoming fragile as features expand.
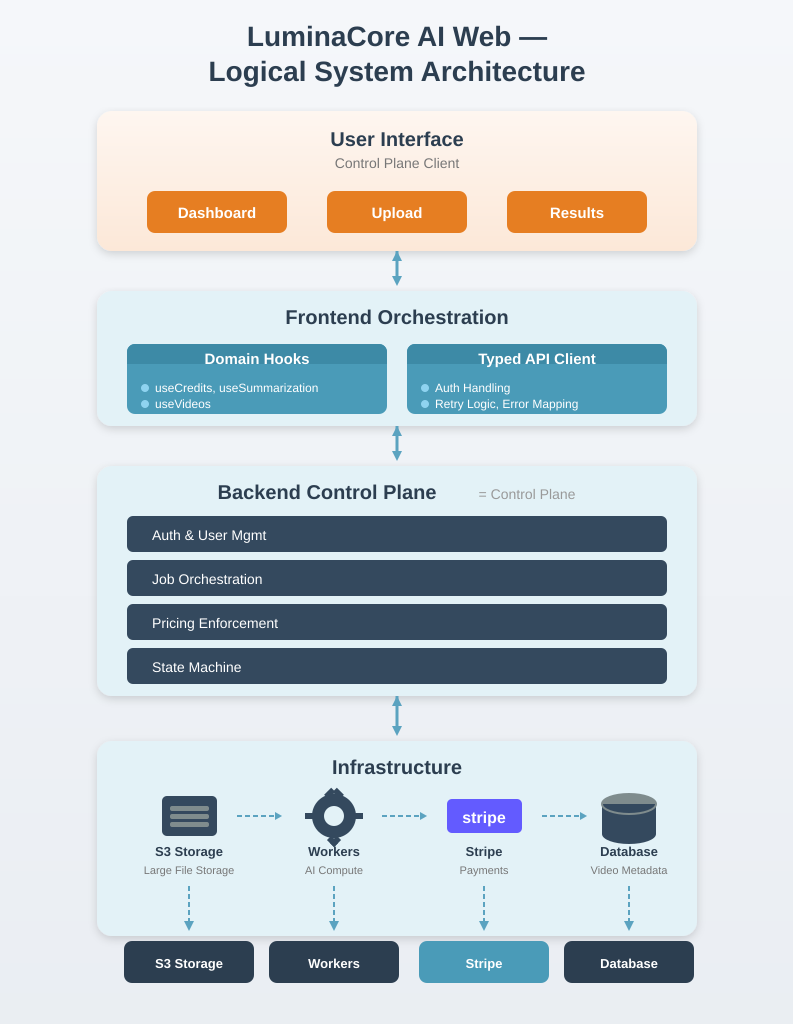
This diagram shows the logical layering of the LuminaCore AI web application. The separation between UI components, hooks, services, and a typed API client allows the frontend to coordinate complex workflows while maintaining clear contracts with the backend.
Public-safe implementation choices
Several implementation decisions are worth highlighting because they directly support reliability and long-term maintainability without exposing proprietary AI internals.
- Next.js App Router separation is used to clearly distinguish marketing and public pages from authenticated dashboard routes, reducing accidental coupling between growth-facing and product-facing concerns.
- Zustand-based state stores manage authentication, credits, and UI state with persistence, allowing long-running workflows to survive refreshes and navigation without complex global state machinery.
- A type-safe API client provides a single integration surface between frontend and backend, handling authentication headers, retries, and error normalisation consistently across the application.
- Polling-based job status updates are used instead of real-time transports. While less fashionable, polling is simpler to reason about, easier to debug, and more predictable under failure—qualities that matter for long-running AI jobs.
Key takeaways
For AI video products, the most difficult challenges typically lie outside the model itself. Reliable systems must handle large asset ingestion, asynchronous workflows, partial failures, economic enforcement, and clean contracts between frontend and backend components.
LuminaCore AI's architecture is designed around these constraints from the outset. By treating the platform as a shared foundation and encoding business models directly into system behaviour, the product remains extensible, predictable, and operationally sound.
Next in the series
The next post focuses on large-file ingestion, examining how presigned URLs, direct-to-storage uploads, and eventual consistency handling form the foundation that allows everything else in the system to scale safely.
Next: Large-File Ingestion Without Killing Your Backend
(Coming soon – link will be added when the post is published.)